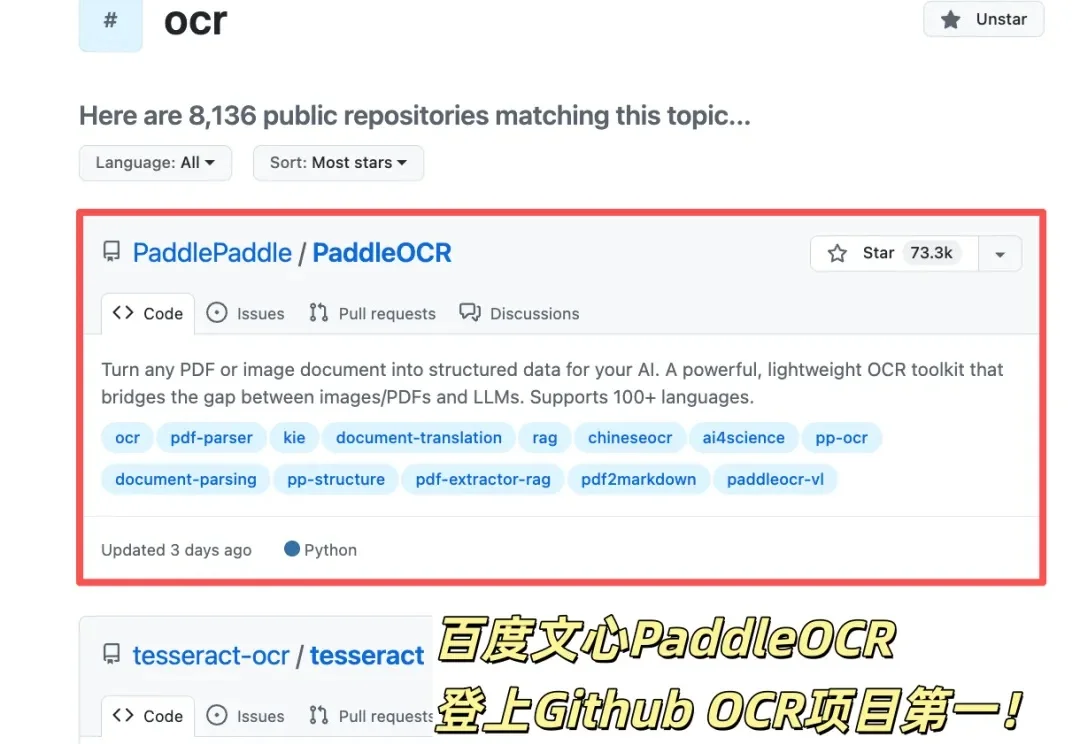
全球OCR新王来自中国开源!GitHub狂揽73300+Star
全球OCR新王来自中国开源!GitHub狂揽73300+StarGitHub OCR项目之王刚刚历史性易主。
来自主题: AI技术研报
6747 点击 2026-03-31 10:29
 搜索
搜索
GitHub OCR项目之王刚刚历史性易主。
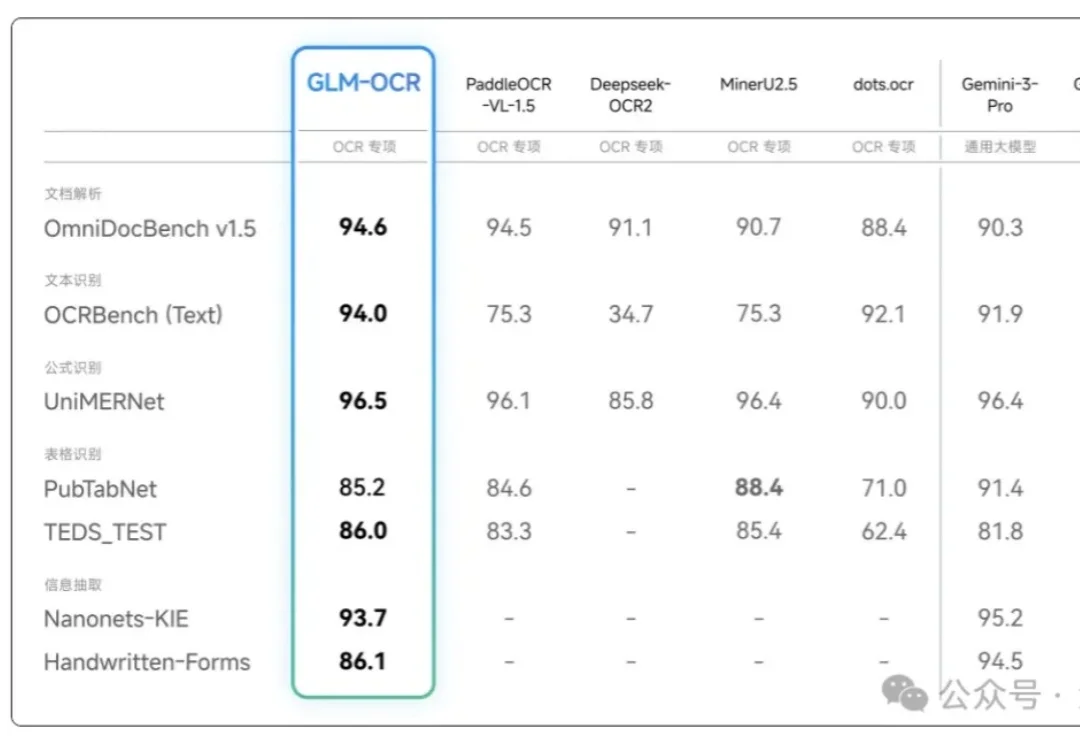
OCR模型究竟能干什么?干得怎么样?

两人小团队,仅用两周就复刻了之前被硅谷夸疯的DeepSeek-OCR?? 复刻版名叫DeepOCR,还原了原版低token高压缩的核心优势,还在关键任务上追上了原版的表现。完全开源,而且无需依赖大规模的算力集群,在两张H200上就能完成训练。

你有没有想过,为什么在这个云计算和AI横行的时代,PDF文档处理依然是企业最大的痛点之一?想象一下这样的场景:一份包含数百页的贷款申请文档躺在银行系统里,等待人工审核,而申请人只能苦苦等待几天甚至几周才能知道结果。与此同时,医院里的医疗记录还在用打印机输出,然后手工传递给下一个医生。

多模态大模型(MLLM)在静态图像上已经展现出卓越的 OCR 能力,能准确识别和理解图像中的文字内容。MME-VideoOCR 致力于系统评估并推动MLLM在视频OCR中的感知、理解和推理能力。
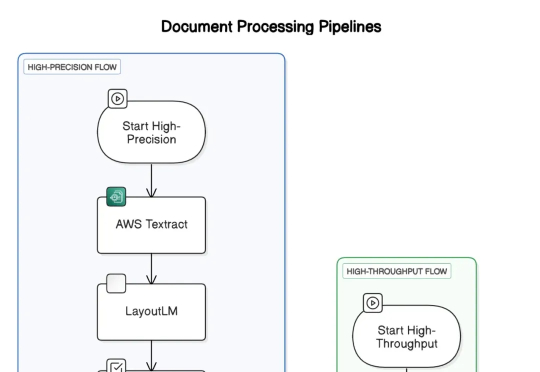
长期以来,光学字符识别(OCR)技术一直是文档数字化的基石。然而,传统的实现方式在应对当今复杂多样的文档时却显得力不从心。在企业领域,文档的形式多种多样,包括扫描的合同、图像、带有嵌入式表格的电子邮件,甚至是手写笔记。基于模式识别和模板的系统无法跟上时代的步伐。一旦输入与预期的规范有所偏离,性能便会出现明显下降,暴露出其脆弱性。

今天,他们自称发布了世界上最好的 OCR API,它能够将复杂的 PDF 文件转换为文本文件,以便 AI 模型处理。现在,所有大模型的输入端格式都是文本,或者规整的、容易识别的文本文件,但这个世界上,还有很多文件是粗糙的,不规整的,难以识别的,它需要依赖强大的 OCR 功能才能转换为文本。